PHP-ETL - Understand the ETL
The Concept
Basic Concept of PHP-ETL
PHP-ETL is structured around a series of operations that process items. Each item represents either a unit of data that can be passed from one operation to the next in a defined chain or the result of an action inside the ETL.
Each operation in the can define specific item types it will handle (each operation can handle any number of different types of items) and any item that doesn’t match an operation’s defined input simply skips that step.
Item Types
Different item types serve distinct purposes in the ETL chain. Here are the basic ones you will need to understand how the etl works.
-
DataItem: This is the most common item type and is typically used to represent rows of data. It can be both input and output in most operations, serving as the primary “payload” of data transformations.
-
ChainBreakItem: This item type, if returned by an operation, signals that the current chain should stop processing the current item and move to the next one. It’s mostly used to filter data inside the chain.
-
StopItem: This item type is automatically created when all items in the chain are processed. It signals the end of processing, allowing operations to finish any remaining tasks, such as persisting data or releasing resources. StopItems should never be manually created, only utilized when they naturally occur at the end of processing.
-
GroupedItem: This item encapsulates multiple row of data within an iterator. When a GroupedItem is encountered, the items it contains are processed as individual DataItems downstream, so a GroupedItem can not be in the input of an operation, they can only be the output.
You can find the list of all native item types here.
How does it works
We will have more detailed real use cases with sample data a bit further in the document.
In the simplest case the chains receive an iterator containing 2 items in input, both items are processed by each chain operation. This could be for example a list of customer. Each operation changes the items. images/concept-flows

In the following example the iterator sends a single item. The first operation will then send GroupedItems containing 2 items. The first item could be a customer, and then we fetch each order of the customer in the operation1.
Operation 2 will then receive each order as a DataItem. It will therefore receive 2 GroupedItems, each containing a single order. Group Items uses iterators, therefore all the orders are not necessarily in memory at the same time. This will depend on your implementation.

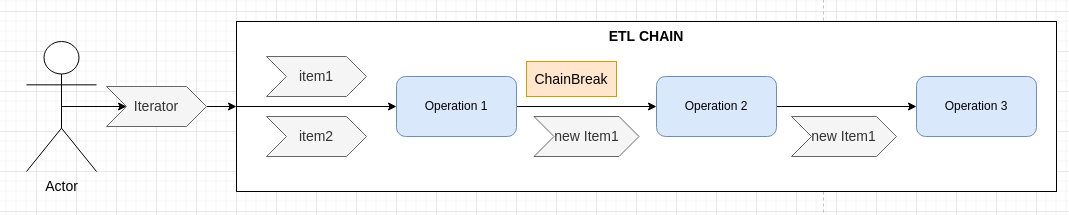
We can also group items, to make aggregations. The chain receives an iterator containg 2 items, the first operation processes both items. It breaks the chain for the first item, and returns an aggregation of item1 & item 2.
This can be used to:
- count the number of customers.
- to get customers grouped by country.
- to create chunks and improving performance while inserting items in a database.
- …
⚠️This kind of grouping can use more memory and should therefore be used with care.
Chains can also be split, this would allow 2 different operations to be executed on the same item.
This can be usefull to :
- store data in 2 different places.
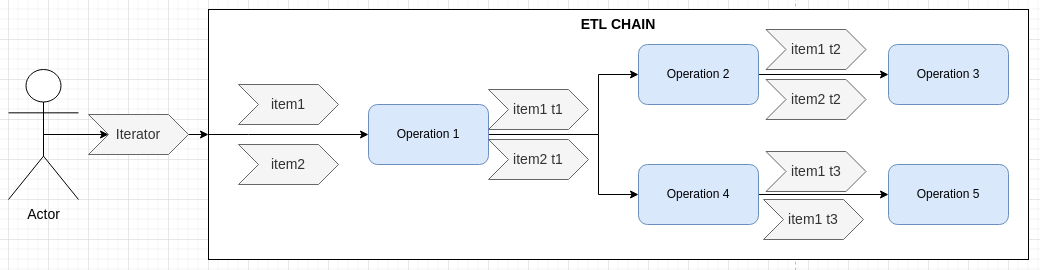
The split operations is among the building blocks of complex executions. There are additional operations to merge multiple branches or to repeat a part of the chain.
Example: Simple CSV Transformation
To demonstrate PHP-ETL’s capabilities, let’s walk through a basic example where we read multiple CSV files, modify each line, and output a new CSV file with selected columns containing the rows of all the files.
Step 1: Read the Input CSV File
The first step is reading the input CSV. PHP-ETL can handle large volumes of data efficiently by processing each row individually, allowing memory-efficient transformations.
This operation reads the input file line by line, it does this by:
- Creating an iterator that will iterate on the csv file.
- Returning a GroupedItem containing this iterator.
The internals in the ETL will then transform each line returned by the iterator into a DataItem and send it to the
next step. While this step will return a single GroupedItem the next step will receive as many DataItem’s as the
lines of the csv file.
use Oliverde8\Component\PhpEtl\OperationConfig\Extract\CsvExtractConfig;
$chainConfig->addLink(new CsvExtractConfig());
Step 2: Transform the Data
Let’s also note that add: false is used to replace existing columns with transformed columns. Without
this option, the operation would add new columns while keeping the original ones. This mean FirstName, LastName
and IsSubscribed would remain in the output.
We’ll use a RuleTransformConfig operation to transform the data. This operation allows us to define custom transformations for each column.
In this example:
- Name is created by concatenating FirstName and LastName with a space.
- SubscriptionStatus copies the IsSubscribed field without any transformation.
use Oliverde8\Component\PhpEtl\OperationConfig\Transformer\RuleTransformConfig;
$chainConfig->addLink(new RuleTransformConfig(
columns: [
'Name' => [
'rules' => [
['implode' => [
'values' => [
[['get' => ['field' => 'FirstName']]],
[['get' => ['field' => 'LastName']]]
],
'with' => ' '
]]
]
],
'SubscriptionStatus' => [
'rules' => [
['get' => ['field' => 'IsSubscribed']]
]
]
],
add: false // Replace existing columns with transformed columns
));
Step 3: Write the Output CSV File
The transformed data is then written to a new CSV file using the CsvFileWriterConfig operation. This operation will write each line one by one but close the file only when the etl finishes.
TIP
We will dive later into how this operations should be used in a context of exporting data. Indeed when exporting data we need to keep a backup of the file and we also need to make sure other processes won’t read the file before we finished writing in it.
use Oliverde8\Component\PhpEtl\OperationConfig\Loader\CsvFileWriterConfig;
$chainConfig->addLink(new CsvFileWriterConfig('output.csv'));
Step 4: Run the Chain Processor
The chain processor is created from the configuration and then initialized with the input file(s).
🐘 Standalone
For instance, the following code will create the chain and process two input files, merging their output:
use Oliverde8\Component\PhpEtl\ChainConfig;
use Oliverde8\Component\PhpEtl\Item\DataItem;
// Create the chain configuration
$chainConfig = new ChainConfig();
// ... add operations as shown above
// Create the chain processor from the configuration
$chainProcessor = $chainBuilder->createChain($chainConfig);
// Process the files
$chainProcessor->process(
new ArrayIterator([
new DataItem(['file' => __DIR__ . "/customers.csv"]),
new DataItem(['file' => __DIR__ . "/customers2.csv"])
]),
[]
);
🎵 Symfony
For instance, the following command will process two input files and merge their output:
./bin/console etl:execute myetl "['./customers1.csv', './customers2.csv']"
Output
The output of this ETL will be a output.csv file containing all customer data from files customers1.csv and customers2.csv.